Fish Speech 教程与资源汇总

介绍与部署教程
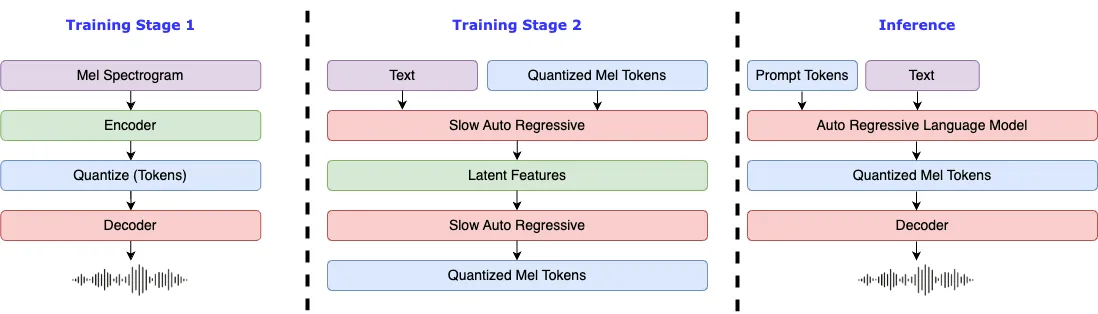
资源汇总:
https://huggingface.co/spaces/fishaudio/fish-agent/tree/main
参考语音
要求
GPU 内存: 4GB (用于推理), 8GB (用于微调)
系统: Linux, Windows
Windows 配置
注意
我们强烈建议非Windows专业用户使用GUI运行该项目。GUI在这里.
Windows 专业用户可以考虑 WSL2 或 docker 来运行代码库。
# 创建一个 python 3.10 虚拟环境, 你也可以用 virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# 安装 pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# 安装 fish-speech
pip3 install -e .
# (开启编译加速) 安装 triton-windows
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
Linux 配置
# 创建一个 python 3.10 虚拟环境, 你也可以用 virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# 安装 pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# (Ubuntu / Debian 用户) 安装 sox + ffmpeg
apt install libsox-dev ffmpeg
# (Ubuntu / Debian 用户) 安装 pyaudio
apt install build-essential \
cmake \
libasound-dev \
portaudio19-dev \
libportaudio2 \
libportaudiocpp0
# 安装 fish-speech
pip3 install -e .[stable]
macos 配置
如果您想在 MPS 上进行推理,请添加 --device mps 标志。 有关推理速度的比较,请参考 此 PR。
警告
compile 选项在 Apple Silicon 设备上尚未正式支持,因此推理速度没有提升的保证。
# create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# install pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# install fish-speech
pip install -e .[stable]
Docker 配置
安装 NVIDIA Container Toolkit:
Docker 如果想使用 GPU 进行模型训练和推理,需要安装 NVIDIA Container Toolkit :
对于 Ubuntu 用户:
# 添加远程仓库 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # 安装 nvidia-container-toolkit sudo apt-get update sudo apt-get install -y nvidia-container-toolkit # 重启 Docker 服务 sudo systemctl restart docker对于使用其他 Linux 发行版的用户,安装指南请参考:NVIDIA Container Toolkit Install-guide。
注:对于中国大陆的用户,您可能需要使用代理来完成相关工具的安装。
拉取并运行 fish-speech 镜像
# 拉取镜像 docker pull fishaudio/fish-speech:latest-dev # 运行镜像 docker run -it \ --name fish-speech \ --gpus all \ -p 7860:7860 \ fishaudio/fish-speech:latest-dev \ zsh # 如果需要使用其他端口,请修改 -p 参数为 YourPort:7860下载模型依赖
确保您在 docker 容器内的终端,然后再从我们的 huggingface 仓库下载所需的
vqgan和llama模型。huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5对于中国大陆用户,可以通过镜像站下载。
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download fishaudio/fish-speech-1.5 --local-dir checkpoints/fish-speech-1.5配置环境变量,访问 WebUI
在 docker 容器内的终端,输入
export GRADIO_SERVER_NAME="0.0.0.0",从而让外部可以访问 docker 内的 gradio 服务。 接着在 docker 容器内的终端,输入python tools/run_webui.py即可开启 WebUI 服务。如果是 WSL 或者是 MacOS ,访问 http://localhost:7860 即可打开 WebUI 界面。
如果是部署在服务器上,更换 localhost 为您的服务器 ip 即可。












Comment