为什么人工智能不使用gpu的共享内存
下面用通俗但技术准确的方式解释:为什么大多数人工智能框架(PyTorch、TensorFlow 等)不主动使用 GPU 的共享内存(shared memory)来存放模型数据或主要计算数据。
🌟 简短回答
GPU 的共享内存只有几十 KB,太小、太贵(需要手动管理)、范围局限(只能在一个 SM 内共享),无法满足 AI 模型的大规模矩阵运算需求。
AI 框架更适合使用 全局显存 + L2 cache + Tensor Core 专用缓存 + 编译器自动优化,而不是让开发者手动摆弄 shared memory。
🔍 详细解释
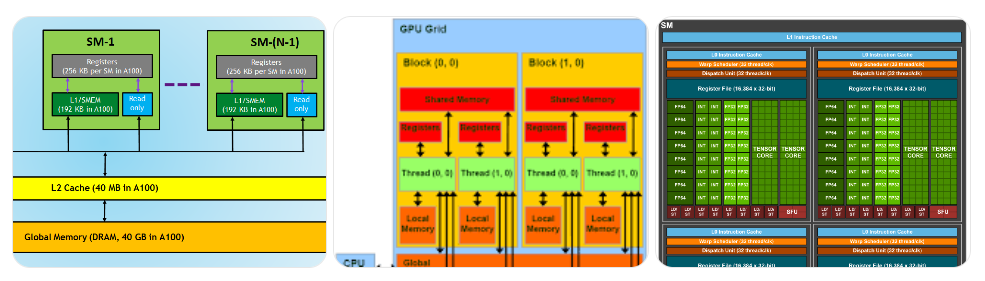
1. 🚫 共享内存太小:根本装不下模型或大矩阵
典型 GPU(例如 RTX 4090 或 A100):
一个 Transformer 模型随便一层的矩阵就是 几 MB − 几百 MB。
而 shared memory 连一个注意力矩阵的 tile 都很难放下,更别说整个运算了。
2. 🚫 只能在一个 SM 的线程块内共享,范围太小
Shared memory 的作用域:
只能在同一个 SM 的同一个 thread block 内共享
block 之间不能共享
kernel 之间不能共享
但大模型训练/推理:
包含几十到上百个 SM
每个 SM 执行不同的 block
需要全局大量矩阵数据共享
➡ shared memory 不能作为框架级的通用机制。
3. 🚫 手动管理困难,容易导致 bank conflict、越界等
使用 shared memory 要处理:
手动分配和布局
bank conflicts
warp-level synchronization
tile/blocking 的调优
AI 框架需要抽象化,不能逼所有人都写 CUDA 内核。
4. ✔ 高性能库已经自动优化了 shared memory 使用
比如:
cuBLAS
cuDNN
FlashAttention
TensorRT
PyTorch 2.0 + TorchInductor
XLA
它们会在内部自动决定:
是否使用 shared memory 作为 tile 缓存
用多大 tile
用什么布局
如何避免 bank conflict
如何结合 Warp Shuffle / Tensor Core
这意味着:
👉 AI 框架不是不用 shared memory,而是让底层库/编译器自动控制。
5. ✔ Tensor Core + 片上 SRAM(Register file)才是加速的关键
现代 GPU(Volta → Ada → Hopper)已经把矩阵运算重心放在:
寄存器(Register file)
Tensor Core 内部 SRAM
L2 Cache
warp-level shuffle
这些比 shared memory 更快、更适合矩阵计算。
很多大模型(如注意力、GEMM)现在使用:
warp shuffle 代替 shared memory 进行数据交换
Tensor Core 直接访问寄存器 tile
L2/显存流水化
这进一步削弱了 shared memory 的必要性。
⭐ 总结:不是不用,而是你看不到
AI 框架自身通常不手动使用 shared memory;
但底层 CUDA kernel(cuBLAS/cuDNN/Fused kernel)在大量使用它。
原因:
Shared memory 太小
覆盖范围太小
手动管理复杂
框架需要抽象而不是写 CUDA
现代 GPU 提供更好的机制(Tensor Core、warp shuffle、片上 SRAM)
因此——
AI 框架借助底层库自动使用 shared memory,而不是让用户显式使用。












Comment